摘要《王者荣耀》当中总共有104名英雄,这些英雄之间会存在一些克制关系与搭配关系一个优秀的阵容应该既能很好地克制对面阵容,也能在内部有着合适的英雄搭配在本项目中,我利用《王者荣耀》官方的「英雄克制系数」与「英雄高胜率双排组合」这两类数据构建了一个电脑玩家: 。
PMCTS3.2,1600PMCTS_{3.2,1600} 该电脑玩家经过「蒙特卡洛树搜索」算法训练后,在 ban/pick 阶段能自动地根据当前的局面选择出一名最优的英雄在模拟的 100 局比赛中,该电脑玩家全部以 100%的胜率战胜了 「 RD 玩家」(随机选择英雄)与「 HWR 玩家」(永远选择胜率最高的英雄)。
另外,本项目也对「蒙特卡洛树搜索」算法进行了一个详细的介绍关键词:王者荣耀,蒙特卡洛树搜索(MCTS),博弈游戏,克制系数,AlphaGo,绝悟AI前言王者荣耀作为一个 MOBA 类游戏,必然会存在一些阵营之间的复杂博弈。
而这些博弈可以分为两个阶段:第一阶段,英雄的ban/pick阶段(如下图所示)在该阶段,双方按照规则轮流ban/pick英雄顶部四个圈代表被禁用(ban)的四名英雄,左右两边各5个方框分布代表双方选取(pick)的英雄阵容。
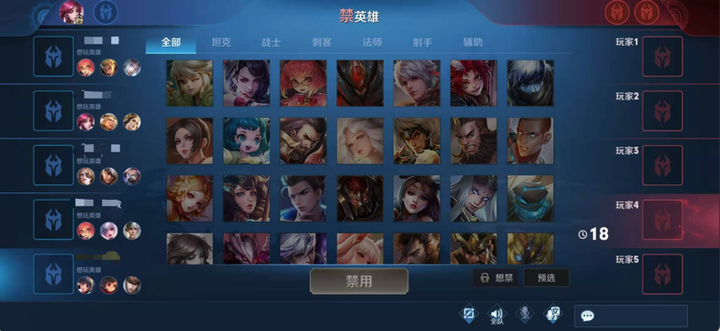
ban/pick阶段游戏界面具体的ban/pick顺序如下图所示:

ban/pick顺序(不同颜色代表不同阵营)按照这个顺序走完后,两个阵营都选出了五名不同的英雄,英雄的ban/pick阶段结束第二阶段,对战阶段双方各自操控上一阶段选出的五名英雄进行对战,最终通过摧毁敌方水晶赢得比赛。
这阶段的不确定性因素非常多,例如玩家技术水平、心情、素质(疯狂点回城)、网速、运气(a不出暴击)、演员、是否开语音、是否发干得漂亮等同时在这阶段,还会涉及队友之间复杂的心理博弈(假装抓人实际蹭线,“东皇没大”,“诸葛没闪”,“全部大残”,“差点反杀”,“被动抢的蓝”)。
这些超出了我的能力范围,因此本项目只考虑第一阶段。由于王者峡谷中每个英雄都有自己独特的技能,不同英雄之间会存在一些克制与搭配关系,这就导致双方在第一阶段会展开一个复杂的博弈:
一个完整的博弈必须有一个确定的结果,因此我们需要将英雄之间的克制与搭配关系进行量化,并且给出一套确定的阵容胜负规则在下文中,我将根据《王者营地》APP 中的英雄克制系数以及英雄两两搭配胜率构建一个「阵容打分函数」。
当双方的阵容都选择完后,打分函数能分别给两方返回一个确定的分数,从而决定胜者这些事情做完后,我们就可以将「英雄的ban/pick阶段」转化为「具有固定步长的博弈游戏」:两个阵营按照ban/pick顺序轮流行动。
两个阵营均知道游戏的完整信息(所有英雄之间的克制关系和搭配关系)游戏在固定步数内结束(14步),并且一定能分出胜负(阵容打分函数)对于这种博弈游戏,有一个通用的方法是使用「游戏树」来辅助决策游戏树中的每一个节点都代表一种游戏状态,玩家每次做完选择后都会从一个节点转移到它的某一个子节点,直至游戏结束。
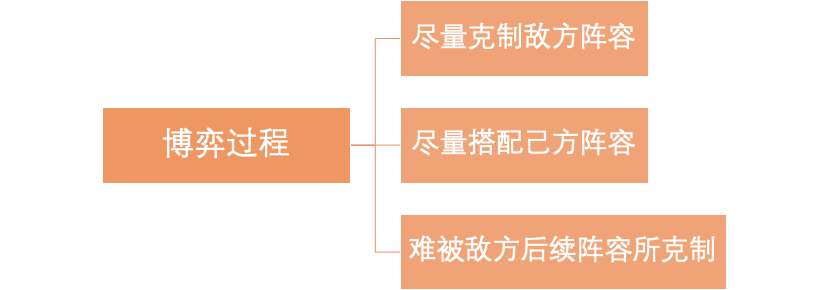
举个简单的例子,对于一个在九宫格上进行的三子棋游戏(三子连成直线则赢),假设游戏进行到了某一步(下图[1]的父节点),接下来轮到绿方落子,那么他的最优决策应该落在哪里呢?这个时候,我们可以借助「游戏树」将后续所有可能的游戏状态全部列出来,最后发现落在最左边会产生两种结果:输(-10)和平局(0),因此落在最左边的平均收益为-5。
类似的,落在中间的平均收益为5,落在右边的平均收益为10所以,绿方的最优落子为最右边
上述方法叫做「MinMax」方法,该方法会将后续所有可能的游戏状态枚举出来,然后选取平均收益最高的一步但是当一个博弈游戏的可能状态数太多时,该方法就失效了例如对于围棋,一颗完整的「游戏树」大约有 10360
10^{360} 个叶节点,我们不可能将所有的状态列举出来同样,在《王者荣耀》的英雄ban/pick阶段,大约有 A21C10410≈1016{A}^1_2{C}^{10}_{104}\approx10^{16}。
个独特的叶节点。要解决这个问题,我们就需要搬出当年谷歌AlphaGo把李世石打出痛苦面具所使用的杀手锏之一:蒙特卡洛树 搜索(MCTS)。

蒙特卡洛树搜索(MCTS)顾名思义,蒙特卡洛树搜索就是将蒙特卡洛方法(Monte Carlo Method)应用到「游戏树」该算法于 2006 年由Rémi Coulom提出,并应用到了围棋领域从此之后,所有最优的围棋电脑玩家全部清一色地使用了该算法。
最后在2016年,谷歌的AlphaGo集齐了 蒙特卡洛树搜索+卷积残差神经网络+强化学习 三大技术,成功战胜世界围棋冠军李世石,人工智能第一次在围棋领域战胜了世界冠军!

接下来,我将简单介绍一下蒙特卡洛树搜索算法的基本思想首先,这个算法的提出就是为了解决游戏状态数巨大时「MinMax」方法失效的窘境既然我们不能获取一颗完整的「游戏树」,那么我们可以折中一下,只往“看起来赢的希望很大
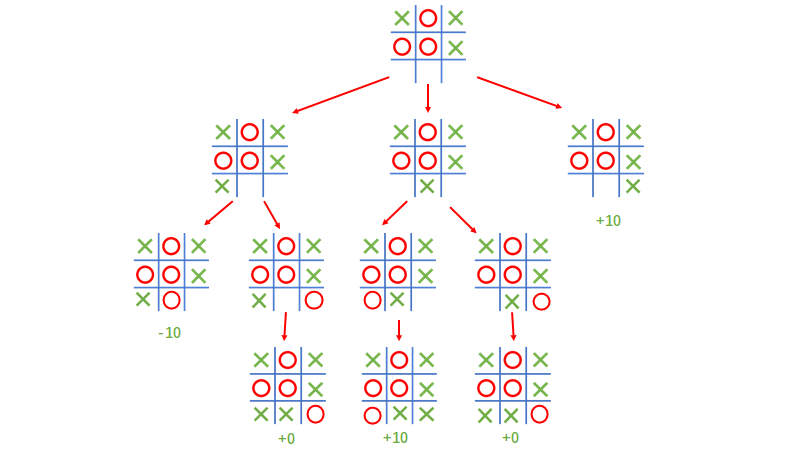
”的方向生长游戏树举一个例子,假设玩家0和玩家1进行一个每一步都只有两种选择的博弈游戏当游戏进行到某一个局面(下图红星)时,玩家0希望通过蒙特卡洛树搜索算法得到接下来应该走蓝色路径还是黄色路径那么,玩家0可以将此刻的游戏状态输入到蒙特卡洛树搜索算法当中,在经过一定步长的计算后,算法会给玩家0返回一颗不完全生长的游戏树(如下图所示):。
根据这颗树上所有节点上记录的信息(见下文“详细解释部分”),玩家0就可以计算出走黄、蓝两条路未来获得的平均收益,从而做出最优的决策简单来说,在这颗树的生成过程可以分为四个阶段的循环(见下图[2]):选择
(Selection),拓展(Expansion),模拟(Simulation),反向传播(Backpropagation):
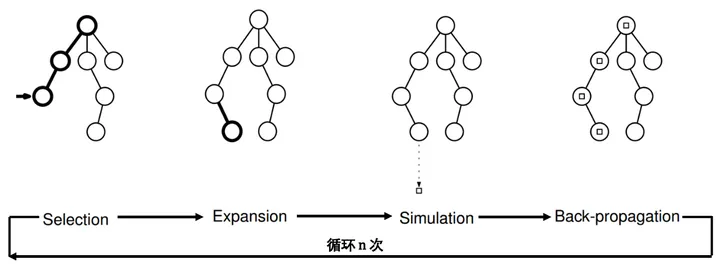
选择(Selection):从根节点(代表当前游戏局面)开始,根据每个节点上储存的信息,按照一定的规则(见下文“详细解释部分”),依次选择子节点往下走,直到遇到一个叶节点拓展(Expansion):到达叶节点后,从该叶节点之后所有可能的「下一步游戏状态」中随机选择一个做为该叶节点的子节点。
模拟(Simulation):从刚才新得到的子节点开始,一直随机往下走,直到游戏结束反向传播(Backpropagation):利用模拟阶段的游戏结果,对上述路径中所有访问过的节点中储存的信息进行更新经过上述四个过程后,我们的游戏树终于生长了一点点(增加了一个叶节点!),并且其中部分节点中储存的信息也得到了更新,然后继续重复这四个过程,最终这棵 将慢慢长大~那什么时候停止呢?这取决于我们的时间资源以及cpu/gpu的价格哈哈,但是我们应该在有限的资源下尽可能长时间地运行该算法。
事实上,L Kocsis 和 C Szepesvári 这两位大佬早就在2006年证明了[3]:当游戏结果用[0,1]之间的分数来表示时,随着循环次数的增加,蒙特卡洛搜索树 将以多项式的速度逼近完整的「游戏树」!

接下来,我将详细介绍一下蒙特卡洛树搜索算法的工作原理我将从下图中的「游戏树」开始,详细地介绍选择,拓展,模拟和反向传播这四个过程具体是怎么工作的树的结构:下图中的「游戏树」是红蓝两个玩家在进行博弈游戏到某一局面(图中。
[4]根节点)时,蓝色玩家试图构建的「游戏树」树中每个节点代表一种游戏状态,每一条线代表一种可能的游戏操作,线一端的游戏状态 A通过该游戏操作变成线另一端的游戏状态B每个节点 viv_{i} 上记录的信息为 。
i=i/i _i= _i/ _i ,其中 NiN_i 代表节点 viv_{i} 有多少次出现在反向传播路径上, WiW_i 代表节点 viv_{i} 有多少次出现在结果为「 节点 viv_i 对应的玩家胜利」的反向传播路径上。
显然, QiQ_i 值越大,代表节点 viv_i 越有可能使其对应的玩家获取胜利。树中所有叶节点的所有可能的「下一步游戏状态」用黑色的实心点表示。
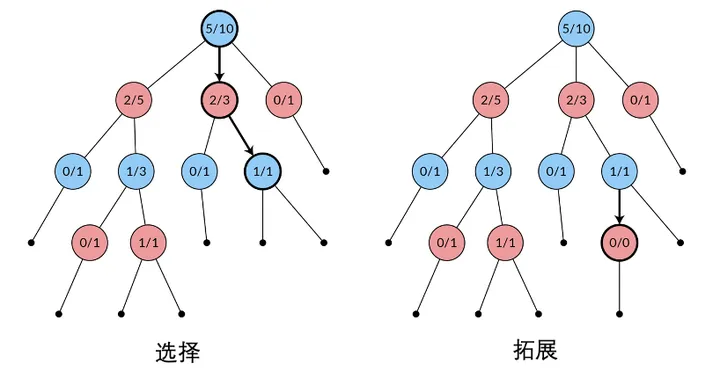
选择(Selection): 前面曾经提到过,蒙特卡洛树会往“看起来赢的希望很大”的方向进行生长那么此阶段的作用就是找出这个方向乍一看这个方向应该为 QiQ_i 值大的方向,因为 QiQ_i 值越大,代表节点 。
viv_i 越有可能使其对应的玩家取得胜利但事实上,这样会很容易导致算法陷入局部最优点 QiQ_i的值是随着循环的次数增加而慢慢逼近真正的 QiQ_i 值的,那么当处在比较早期的「树的生长阶段」时, Q
iQ_i 值容易出现波动在蒙特卡洛树搜索算法中,真正的生长方向由下面的UCB-1(Upper Confidence Bound-1[5])公式确定: UCB-1=Qi+cln(Np)NiUCB\text{-1} = Q_i + c\sqrt{\frac{ln(N_p)}{N_i}}\\。
即从根节点开始,每次向UCB1值大的子节点前进,一直走到叶节点,选择(Selection)阶段结束。
(UCB1公式中 NpN_p 代表父节点出现在反向传播路径上的次数上式第二项的加入会使得那些很少被探索的方向( NiN_i 非常小的节点)更容易获得比较大的UCB1值,从而更容易在本次循环中得到被探索的机会。
而其中c值则代表了在「收益暂时很高」与「潜力可能很大」两个方向之间的权衡)拓展(Expansion): 按照UCB1公式,在选择阶段一路走到叶节点后,我们需要对其进行拓展即随机从该叶节点下面的黑色的实心点中选择一个作为其子节点,并且标上统计信息:0/0。
(若该叶节点已经代表了游戏的结束,那么不需要拓展)模拟(Simulation): 当我们生成一个新的节点后,我们将从此节点对应当游戏状态开始开始,随机地往下进行游戏(下左图),直到游戏结束此过程中的路径信息不作记录,仅记录最终的游戏结果。
反向传播(Backpropagation): 模拟阶段结束后,我们将得到一个游戏结果(下右图中游戏结果为蓝方胜利),那么接下来我们需要反向沿着之前走过的路径,将这一次的游戏结果更新到路径中的节点中这些节点的 。
NiN_i 值全部+1,其中属于胜利方(蓝方)操作后的节点的 WiW_i 值全部+1例如,下右图中红框部分的节点的NiN_i 值和WiW_i 值全部+1,因为该节点对应的是胜利方(蓝方)操作后的游戏状态。

综上,经过上面四个步骤后,我们的「游戏树」发生了如下变化:(1)增加了一个节点。(2)其中一条路径上的统计信息得到了更新。

继续循环这四个步骤,我们的「游戏树」将越长越大,会越来越逼近完整的「游戏树」树的使用: 当我们认为这棵树生长地差不多时,就可以拿来帮我们做决策了蓝方把这颗「游戏树」拿过来,看一眼第二行哪一个节点上的 Q
iQ_i 值最大,然后进行相应的游戏操作就行了(看 QiQ_i值而不看UCB1值是因为我们认为树已经够大了,此时节点上的QiQ_i值会逼近真正的QiQ_i值)值得注意的是:这棵树只能使用一次即下次蓝方又需要机器进行辅助决策时,他需要再次生成一颗树。
事实上,由于蒙特卡洛树搜索算法应用的场景是,每一步可能的游戏操作都非常多的博弈游戏对于一颗经过有限时间生长出来的树来说,越往下节点将越稀疏,此时他的预测能力会越来越弱前人工作接下来我们来看看学术大佬们拿这个牛逼的算法做的一些牛逼的工作(以下内容只是我个人浅显的理解,如果有错误还请大佬能指出):
谷歌DeepMind,AlphaGo[6] 首先,如果直接将MCTS应用到围棋中会存在一些问题:(1)一局围棋的平均步长为150步,因此MCTS会花很多时间在模拟阶段(2)在拓展节点阶段,一次只能拓展一个节点,效率太低。
(3)在选择阶段,MCTS采用UCB1公式,该公式含有对数计算,会增加计算机的负担 针对以上问题,DeepMind主要做了两个优化首先,将UCB-1公式替换成了PUCT( Polynomial Upper Confidence Trees )公式:
PUCT=Qi+cPiNpNiPUCT = Q_i + cP_i\frac{\sqrt{N_p}}{N_i}\\ 可以看到,对数函数被替换成了根号,并且第二项多了一个系数 PiP_i ,代表节点 vi
v_i 被其父节点访问的概率这样的话,每个节点需要储存的信息变为了 (Wi,Ni,Pi)(W_i,N_i, P_i) 而 PiP_i 的计算方法就和他们做的第二个优化有关:引入神经网络AlphaGo利用大量人类的棋谱以及自我对弈的结果(强化学习)训练了两个神经网络:。
策略神经网络(policy network)和价值神经网络(value network)输入当前的节点(游戏状态)后,策略神经网络会返回所有可能的子节点的落子概率 PiP_i,而价值神经网络会返回对应子节点后续的获胜概率。
经过上面两个优化后,MCTS的训练效率大大提升,最后成功把李世石干趴!DraftArtist[7] 这篇文章于2018年首次将MCTS应用到了MOBA类游戏的阵容选择模型问题具体来说,他们考虑的游戏是 Dota 2,当时游戏总共有114名英雄。
由于游戏步长(固定22步)相对于围棋来说大大降低,他们采用的是纯 MCTS 算法正如前面所说,一个博弈游戏必须要有一个确定的结果,因此他们需要一套确定的阵容胜负规则事实上,他们拥有一个含有 3,056,596 场 Dota 2 对局阵容以及游戏结果的庞大数据集,他们利用这个数据集训练了一个神经网络作为阵容打分函数。
最终,他们训练了很多「循环次数为n」以及「UBC1公式中c的取值为 c0c_0 」的MCTS电脑玩家(UCTn,c0UCT_{n,c_0} ),然后让这些电脑玩家和其他「非MCTS算法构建」的电脑玩家进行多次对局,最终根据阵容打分函数的评估结果来评估这些电脑玩家的实力。
主要结果如下:
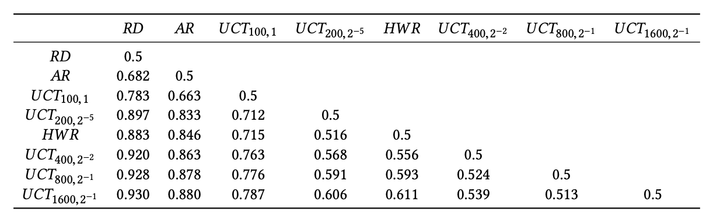
其中 RD 代表「随机选择英雄」的电脑玩家,HWR 代表「永远选择胜率最高的英雄」的电脑玩家,AR代表「根据数据集中英雄的搭配关系构建」的电脑玩家,表中 (i,j)(i,j) 位置的值代表玩家 ii 对战玩家
kk 的胜率可以看到所有MCTS玩家的实力都是要强于「非MCTS算法构建」的电脑玩家的腾讯AI Lab, “绝悟”AI(JueWuDraft)[8]相信玩过王者荣耀的朋友都知道绝悟有多强,放一个绝悟露娜一打三的视频你们感受一下:。
绝悟露娜 3秒 7大 按键解析b23.tv/tKjCLj当然,这是属于对战阶段的博弈,和MCTS没有关系事实上,绝悟同样有优秀的ban/pick技能在论文[8]中,绝悟被设计成不仅能应对单局比赛(22步),而且能应对BO3(66步)、BO5(110步)这种职业比赛赛制,因此需要借助神经网络来加快训练。
绝悟在这阶段采用的训练方式和AlphaGo是类似的:同样引入了策略神经网络(policy network)和价值神经网络(value network)另外,绝悟采用了两种基于神经网络的阵容打分函数,分别由「3千万的AI对战结果」以及「3千万的人类真实对战结果」作为训练集来训练得到。
最终,在论文中展示了绝悟AI( JueWuDraft )与「纯MCTS玩家(DraftArtist)」,「RD」玩家以及「HWR」玩家的单局对战结果:
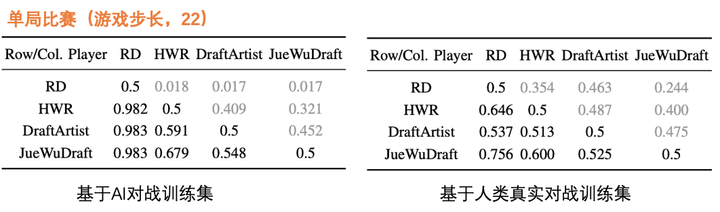
可以看到「JueWuDraft」在所有模型中表现最好但是由于是单局比赛,游戏步长固定22步,神经网络的引入带来的优势不明显,最终「JueWuDraft」对「纯MCTS玩家(DraftArtist)」的优势在两个训练集上都不大(JueWuDraft胜率分别领先4.8%与2.5%)。
而对于BO3和BO5的赛制,神经网络的优势就体现出来了:

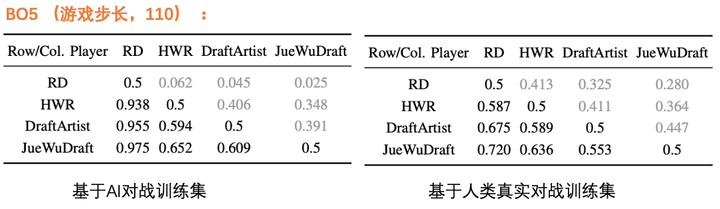
可以看到,在BO5的赛制中,「JueWuDraft」对战「纯MCTS玩家(DraftArtist)」的胜率达到了60.9%与55.3%我的项目讲完「大佬」的工作,接下来轮到我这个「菜鸡」出场了在上面介绍的三篇论文中,无一例外地都同时使用了「。
MCTS」与「神经网络」:AlphaGo 与 JueWuDraft 面对的问题都是「游戏步长很长的博弈问题」,因此加入策略神经网络与价值神经网络来预测「落子/选英雄」概率和对应的胜率这样就能在「拓展阶段」直接生成大量子节点,并且也不需要再进行漫长的「模拟阶段」,从而可以让其在短时间内生成一颗很大的「游戏树」,大大加快MCTS的效率。
DraftArtist 面对的问题是单局 Dota 2 游戏,游戏步长只有22步,因此他们使用「纯MCTS算法」事实上,从 JueWuDraft 论文中的结果也可以看出,在只考虑单局游戏时,神经网络的引入带来的实力提升并不大(但是树的生成速度会加快)!另外,DraftArtist 利用一个超过300W条数据的庞大数据集训练了一个神经网络,最后根据双方的阵容来预测胜方。
那么,我们在缺少玩家真实对局结果的数据集的情况下,能否构建/复现出一个与 DraftArtist 或 JueWuDraft 类似的「阵容选择模型」呢?由于缺少真实对局结果的数据集,我们需要通过其他方式来构建一个「
阵容打分函数」(见下文),该函数的输入为双方阵容,输出为双方各自获得的分数在 MCTS的「模拟阶段」,当游戏结束时,阵容打分函数将被用来决定胜负,然后将游戏结果进行反向传播另外,为了加快树的生成速度,我们也可以和 AlphaGo 与 JueWuDraft 一样,采用「。
PUCT版MCTS算法」不同的是,他们使用大量历史数据集以及自我对弈来构建一个「策略神经网络」来预测「落子/选英雄」的概率,从而给出PUCT公式中的 P_i 但由于我们没有历史数据集,我们将直接采用「各个英雄的出场率」来代替「策略神经网络」。
事实上,各个英雄的出场率正是由所有玩家的真实对局记录算出来的,这在一定程度上可以近似真正的落子概率 P_i 综上,本项目将采用如下「PUCT版MCTS算法」试图构建/复现一个《王者荣耀》的最优阵容选择模型:。
相关代码(后续将整理)在我的 Github 中阵容打分函数在这一部分,我将根据《王者荣耀》中的「英雄克制关系」和「英雄搭配关系」来构建一个「阵容打分函数」对于阵容 A 和阵容 B ,我们期望这个「阵容打分函数」满足如下要求:。
阵容 A 越克制阵容 B ,阵容 A 的分数应该越高阵容 A 内部的英雄搭配越好,阵容 A 的分数也应该越高幸运的是,王者荣耀官方对英雄之间的克制、搭配关系进行了量化(见下图)英雄克制关系:对于每一个英雄,都给出了这个英雄最「克制」与「被克制」的英雄(Top3)以及相应的克制系数。
英雄克制关系,图片来源于《王者营地》APP英雄搭配关系:对于每个英雄,都给出了与这个英雄「双排」或「三排」胜率最高的组合(Top3)以及相应的胜率。
英雄搭配关系,图片来源于《王者营地》APP通过爬虫获取到这些数据后,我将构造两个辅助打分函数:克制关系打分函数, kz_{s_1,s_2}:输入阵容 s_1 与 s_2 后,返回「 s_1 中所有英雄对
s_2 中所有英雄的克制系数之和」搭配关系打分函数, dp_s :输入阵容s后,返回「s中所有高胜率双排组合的胜率之和」那么最终的阵容「阵容打分函数」可以定义为:\begin{align} Score(s_1,s_2)& =f(kz_{s_1,s_2},kz_{s_2,s_1})+d\cdot f(dp_{s_1},dp_{s_2})\\ \end{align}\\ 。
其中,\ f(a,b) \equiv sign(a-b)\cdot[\frac{max(a,b)-min(a,b)}{min(a,b)}]\\0">Score(s_1,s_2)>0 则代表阵容 s_1
获胜,其中常数 d 控制了「克制关系」与「搭配关系」的相对投票权那么,我们如何确定最优的 d 呢?有一个巧妙的方法就是采用暴力搜索法,对于每一个 d 的取值都随机生成 40w 对英雄阵容,然后用该 。
d 值对应的阵容打分函数进行打分,统计每个英雄的胜率,将结果储存为一个向量 \vec{w_{d_i}} 最优的 d 对应的向量 \vec{w_{d_m}} 与真实的英雄胜率向量 \vec{w_{0}} 应该有最大的Pearson相关性!在搜索了22个
d 值后(见下图),可以看到当 d=0.1 时,Pearson系数达到峰值。因此 d 的最优取值为:d=0.1 .
其中Pearson1对应对向量进行 t 操作后,两个向量之间的Pearson相关系数( t 操作为:若胜率大于0.5则变换为1,否则变换为0.)构建完「阵容打分函数」后,我们终于可以把它扔进「PUCT版MCTS算法。
」中进行实验了实验结果前文提到,在PUCT公式中有一个参数 c ,代表了在「收益暂时很高」与「潜力可能很大」两个方向之间的权衡,最优的取值 c 视具体的情况而定另外,最终生成的「游戏树」的大小取决于MCTS算法运行的时间(循环的次数 n ),n 越大性能越优秀,但是训练时长也越长。
在实验中,我将采用格点搜索法构建不同的「PUCT版MCTS」玩家 PMCTS_{c,n} ,然后分别与电脑玩家「RD」(随机选择英雄)、电脑玩家「HWR」(永远选择胜率最高的英雄)进行100局对战,最后根据
PMCTS_{c,n} 玩家的胜率和平均运行时长来决定最优的 (c,n) 取值。实验结果如下:「 PMCTS_{c,n} 玩家」 VS 「 RD 玩家」,100局胜率:
2.「 PMCTS_{c,n} 玩家」 VS 「 HWR 玩家」,100局胜率:
可以看到,即使是每一步循环1600次,在我的个人电脑(2.2 GHz 四核Intel Core i7,充电状态 )上也只需要运行不到 6s 的时间,而真实游戏中玩家有 20s 的时间做抉择另外,由上面两个表可知, 。
c = 2^4/5=3.2 时,PMCTS玩家的实力最强综上,最优的电脑玩家为: PMCTS_{3.2,1600} 筛选出最强的电脑玩家后,我们来看一个具体的例子下图是「 PMCTS_{3.2,1600}。
」玩家与「RD」玩家的某一次对局记录。
图中箭头(蓝色、黄色)代表英雄A沿着箭头方向克制英雄B, 线上的数字代表对应的「克制系数」红色的箭头代表高胜率双排组合,线上的数字代表相应的双排胜率过程如下:「 PMCTS_{3.2,1600} 」玩家选择「。
蔡文姬」「RD」玩家选择「廉颇」与「盘古」「 PMCTS_{3.2,1600} 」玩家选择「蒙犽」与「澜」「蒙犽」同时克制「廉颇」与「盘古」,并且和「蔡文姬」双排的胜率很高「澜」的选择就更妙了:一方面「澜」与「蔡文姬」的双排胜率非常高,更重要的是「澜」的选择可以。
防止本队的阵容后续被对面所克制!在本例子中,「RD」玩家后续选择的英雄「西施」会克制「蔡文姬」,但是「西施」会被上一步选出来的「澜」克制,若对面同样也是「 PMCTS_{3.2,1600} 」玩家,那么由于「澜」的出场它将不会选择「西施」。
「RD」玩家选择「裴擒虎」与「西施」「 PMCTS_{3.2,1600} 」玩家选择「安琪拉」与「关羽」「安琪拉」克制「盘古」,同时与「蔡文姬」双排的胜率很高另外,虽然「关羽」已经被对面的「盘古」所克制,但是「关羽」对「西施」的克制更厉害,因此收益更高。
「RD」玩家选择「伽罗」。可以看到,「 PMCTS_{3.2,1600} 」玩家在对战中的确能较好地满足下面的条件:
不过,当前的「 PMCTS_{3.2,1600} 」玩家会倾向于派「蔡文姬」作为第一个英雄出场,因为该英雄与非常多的英雄都能有着较高的双排胜率,从而使得玩家在后续获得较大的收益其中一个很重要的原因是:现阶段我只能获取到「英雄克制」与「英雄搭配」TOP3 的数据,这些数据会存在一些偏向(例如蔡文姬拥有的高胜率双排组合数量远超第二名)。
在未来的工作中,我希望能获取更多的「英雄克制」与「英雄搭配」关系,随着数据逐渐地补充,「英雄克制」与「英雄搭配」关系会越来越逼近真实的关系,「PMCT」玩家的表现也会越来越好!最后讨论在本项目中,我利用《王者荣耀》官方的「英雄克制系数」与「英雄高胜率双排组合」这两类数据构建了一个阵容打分函数。
然后,我将该函数应用到「PUCT版MCTS算法」中,构建了一个电脑玩家: PMCTS_{3.2,1600} 该电脑玩家在《王者荣耀》「单局游戏」内的 ban/pick 阶段,能自动地根据当前的局面选择出一名最优的英雄。
在模拟的 100 局比赛中,该电脑玩家全部以 100% 的胜率战胜了 「 RD 玩家」(随机选择英雄)与「 HWR 玩家」(永远选择胜率最高的英雄),实力非常强!具体的训练流程为:
本项目针对 AlphaGo 与 JueWuDraft 的简化:由于缺少真实的英雄对局记录数据集,我无法训练用于给出落子概率的「策略神经网络」以及用于预测后续胜率的「价值神经网络」但是,根据 JueWuDraft 的。
论文中结果:在《王者荣耀》中,若只考虑单局游戏,神经网络带来的「实力收益」非常小,即只能加快树的训练速度因此,在本项目中我也采用与他们同样的「PUCT版MCTS算法」,然后用「各个英雄的出场率」来代替「策略神经网络」,用「阵容打分函数」代替「价值神经网络」。
这样的话,既可以获得训练速度的提升,也不会降低PMCTS玩家的实力2. 本项目针对 JueWuDraft 与 DraftArtist 的优化:在 JueWuDraft 与 DraftArtist 这两个模型中都没有考虑英雄的位置冲突问题,即他们会允许5个法师这样的阵容存在。
由于在实际的游戏当中,绝大部分的阵容都是满足每一个位置只有一个英雄,因此在训练阶段加入英雄位置的限制会大大降低后续可能的游戏状态,从而获得速度的提升JueWuDraft 没有考虑英雄的禁用阶段,而这是一个很重要且不可避免的阶段。
因此,本项目在训练过程中也考虑了「英雄的禁用阶段」3. 本项目后续 To do :「阵容打分函数」还有待优化:目前,《王者营地》APP中每个英雄的「克制与被克制系数」、「双排/三排高胜率组合」全部都只有 TOP3 的数据。
信息量太少,会导致阵容打分函数不够精确事实上,由于现在有 104 名英雄,那么理论上应该有 104\cdot104=10,816 条数据但即使我爬取了1月4号-1月14号总共11天的数据,最后也只能获取到 5% 左右的数据。
虽然根据现有的「阵容打分函数」训练出来的最强电脑玩家 PMCTS_{3.2,1600} 在对战其他电脑玩家时以碾压的优势取胜,但离「实战可用性」还有一段距离因为现在的「胜负标准」完全由「阵容打分函数」决定!当我们有足够的信息量时,我们就可以构建一个足够精确的「阵容打分函数」,从而可以真正辅助我们来选/禁英雄!。
帮助玩家选择要练习的新英雄:当前有超过90%的王者段位以下的玩家,而其中大部分玩家都只会玩2-3个英雄当这些玩家想新练一个英雄上分时,他应该选哪一个英雄呢?如果从ban/pick的角度来看的话,一个玩家的英雄池越深,就越能拿出相应的英雄来counter对面以及搭配本队的阵容。
假设这名玩家现有的英雄池为 SetA ,他想从 SetB 中选一名英雄来练习那么我们可以遍历SetB 中所有新英雄 b_i ,各自训练一个 PMCTS_i 电脑玩家在PMCTS_i的训练过程中,随机限制在某一步中可选的英雄池为 。
SetA\cup b_i ,这样的话相当于帮助该玩家模拟了每一种情况下他的英雄池的实力最后,将这些 PMCTS_i 电脑玩家分别与「不做英雄池限制」的电脑玩家 PMCTS_{c_0,n_0} 对战,其中胜率最高的 。
PMCTS_i对应的英雄 b_i 就是他应该练习的英雄参考^Introduction to Monte Carlo Tree Search: The Game-Changing Algorithm behind DeepMind’s AlphaGo。
https://www.analyticsvidhya.com/blog/2019/01/monte-carlo-tree-search-introduction-algorithm-deepmind-alphago/
^Chen, Zhengxing, et al. "The art of drafting: a team-oriented hero recommendation system for multiplayer online battle arena games."Proceedings of the 12th ACM Conference on Recommender Systems. 2018.
https://arxiv.org/pdf/1806.10130.pdf^Kocsis, L. and Szepesvári, C., 2006, September. Bandit based monte-carlo planning. InEuropean conference on machine learning(pp. 282-293). Springer, Berlin, Heidelberg.
https://link.springer.com/content/pdf/10.1007/11871842_29.pdf^General Game-Playing With Monte Carlo Tree Search
https://medium.com/@quasimik/monte-carlo-tree-search-applied-to-letterpress-34f41c86e238^Upper Confidence Bound-1
https://link.springer.com/content/pdf/10.1023/A:1013689704352.pdf^谷歌DeepMind,AlphaGohttps://deepmind.com/research/case-studies/alphago-the-story-so-far
^The Art of Drafting: A Team-Oriented Hero Recommendation System for Multiplayer Online Battle Arena Games
https://arxiv.org/abs/1806.10130^ab腾讯AI Lab, “绝悟”AIhttps://arxiv.org/abs/2012.10171
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。

发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。