
你是否还在为考证烦恼?是否不知从何学起?
学习部每周的办公软件小课堂!这里总有你想要的!

很多人留言给小编说不太理解表格自动排序今天给大家简单的推送一下
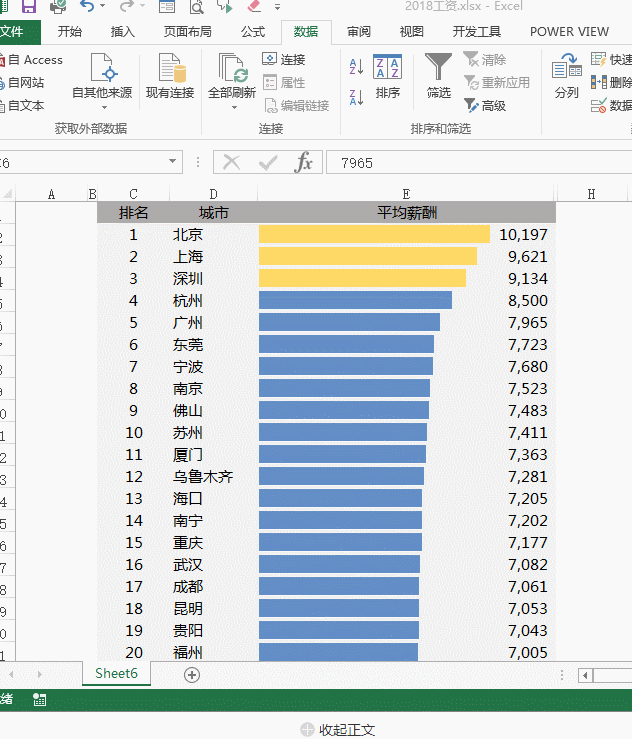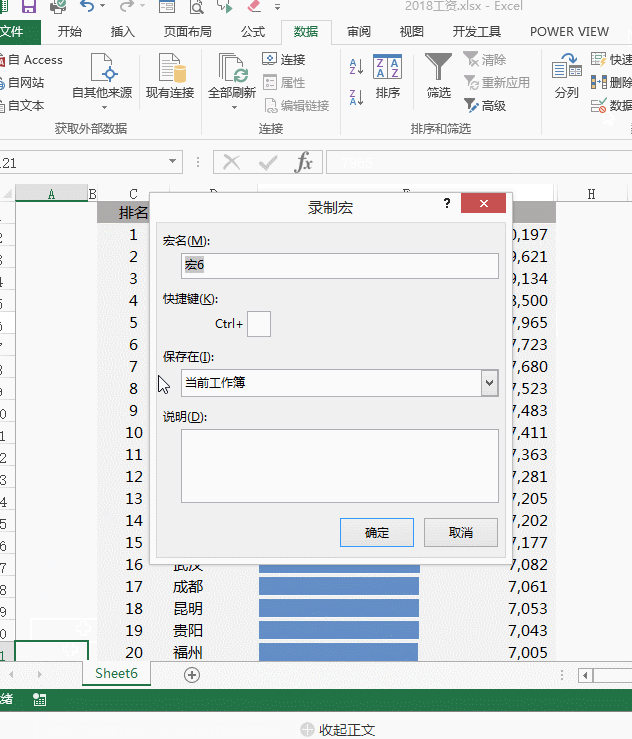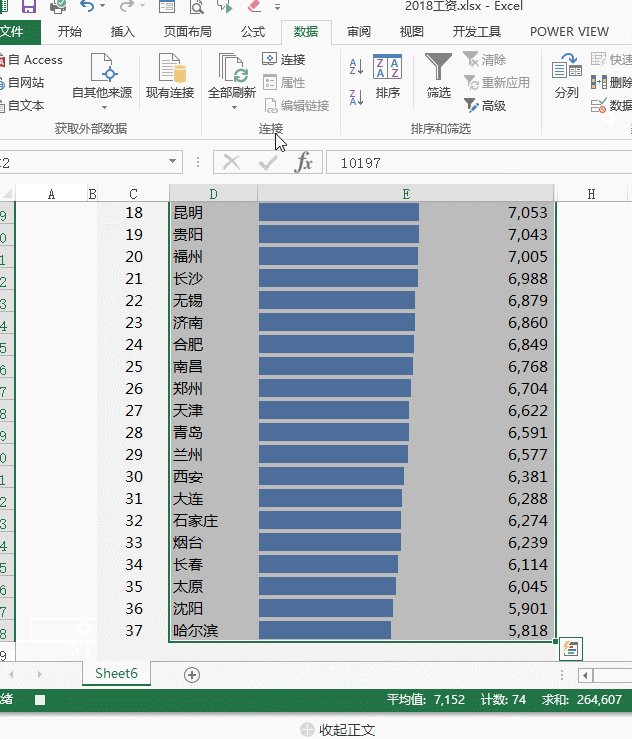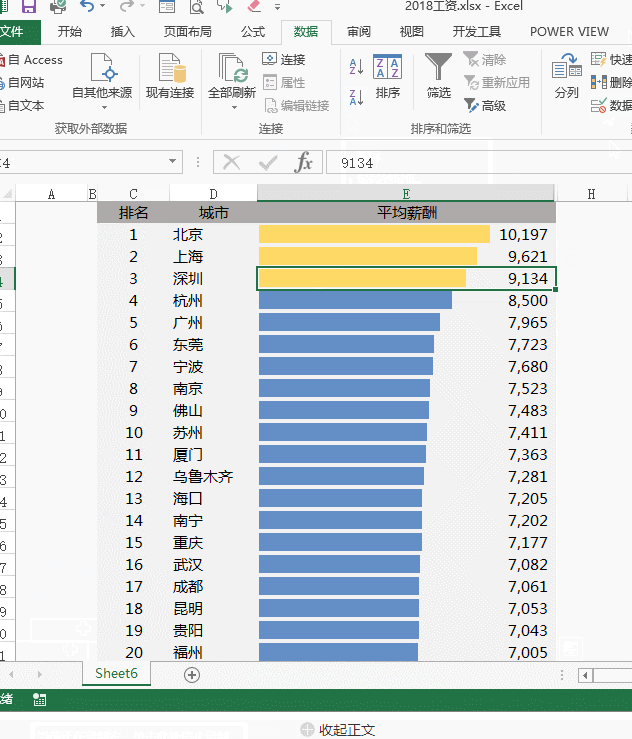
让Excel表格自动排序怎么自动排?先看效果:蓝色从网上下载的2018年各大城市最新平均工资排行表
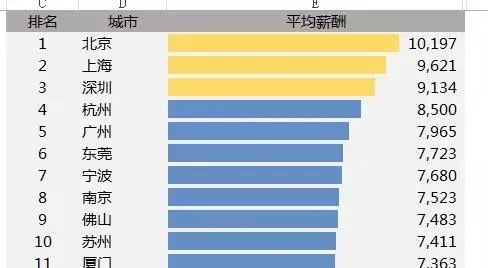
当改动其中一个城市的平均工资时,比如广州由7965改为10000,整个表格的顺序会自动调整:


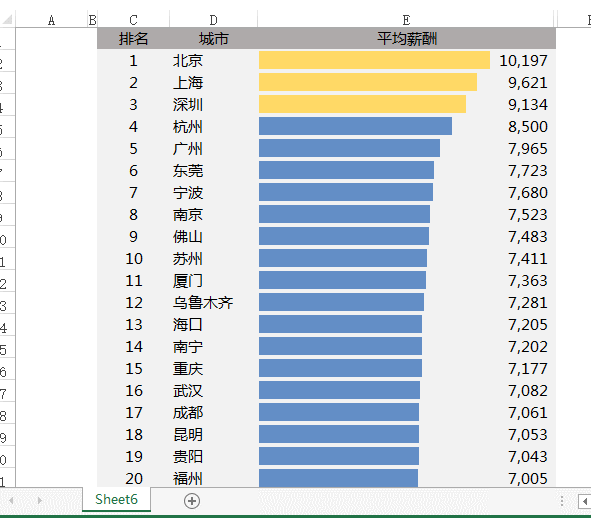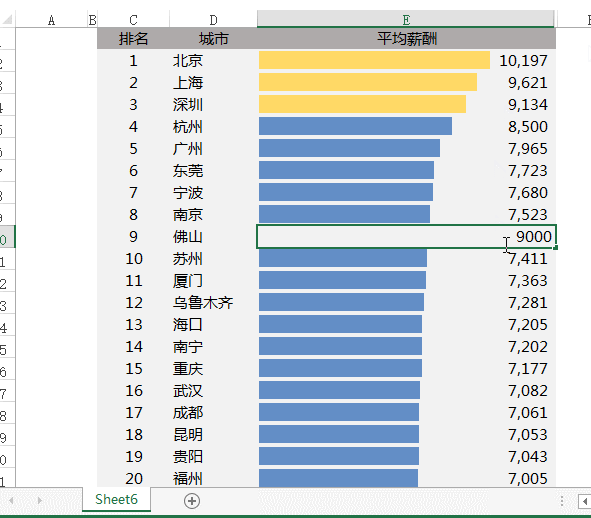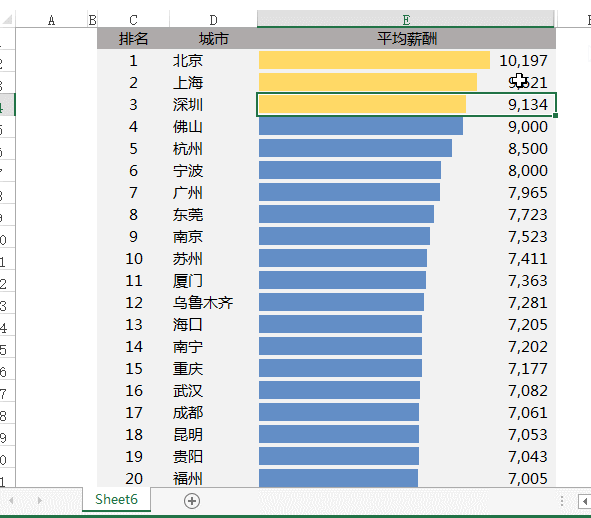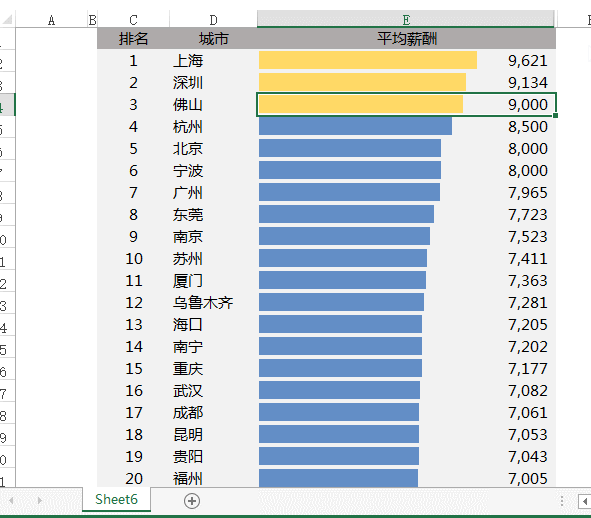
设置完成!修改数据后,表格就可以自动调整顺序了:

END来源 | 网 络编辑 | 卢新润审核 | 黄捷浓责编 | 罗永珍
让先进成为个性,让优秀成为习惯
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。






发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。